Building and Evaluating Retrieval-Augmented Generation (RAG) Applications 🔎
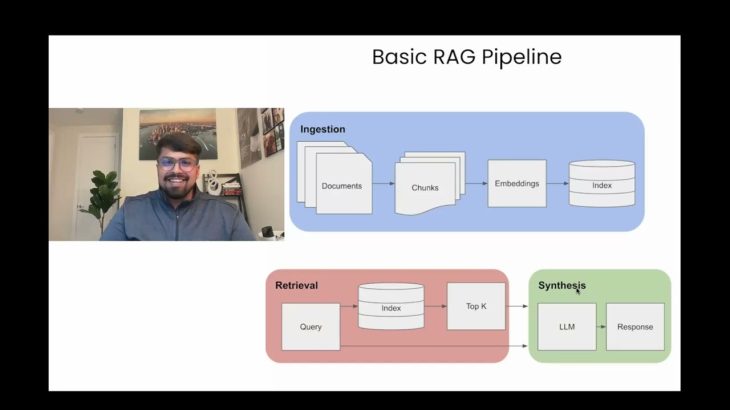
A Basic RAG Pipeline consists of three steps:
– Ingestion: Split documents into chunks which are embedded into a Vector DB
– Retrieval: Query your Vector DB to retrieve top K similar chunks
– Synthesis: Use retrieved chunks as context for LLM to synthesize response
Use the RAG Triad of metrics to evaluate your RAG Application:
– Context Relevance: Is the retrieved context relevant to the query?
– Groundedness: Is the response supported by the context?
– Answer Relevance: Is the response relevant to the query?
Image Credits: DeepLearning.AI
Subscribe to Generative AI with Varun to learn more about RAG and Generative AI Fundamentals.
#ai #generativeai #llm #ml #machinelearning #artificialintelligence #chatgpt #openai #google #gemini #copilot #microsoft #meta #amazon #aws





